
[ad_1]
در اجلاس سالانه خود (20 تا 21 مه در بوستون) ، رد سرور استنتاج را برای مدل های AI آموزش دیده معرفی کرده است که با پلت فرم و با نیازهای سخت افزاری کم کار می کند.
این سرور مبتنی بر پروژه مجازی LLM (VLSM) است که نه تنها مدل های استنتاج را مجازی می کند ، بلکه به طرز ماهرانه ای مدیریت ذخیره آنها را به منظور استفاده کارآمد از منابع سخت افزاری ساختار می کند. قرمز یک کانتینر سازی را با Kubernetes انتخاب کرده است ، به طوری که سرور روی تمام سیستم عامل های کانتینر و HyperScalers اجرا می شود ، از Kubernetes پشتیبانی می کند و سخت افزار لازم را ارائه می دهد: GPU های NVIDIA ، AMD یا Google. استفاده از لبه نیز امکان پذیر است. علاوه بر این ، طبق گفته سازنده ، تمام مدلهای رایج می توانند در آن کار کنند.
کاربران همچنین می توانند از چندین ظرف بیش از چندین ظروف استفاده کنند ، که Red دارای LLM-D است ، پروژه ای که این شرکت به همراه Google ، IBM ، NVIDIA و دیگران فعالیت می کند.
ظرف تمام شده روی بغل کردن صورت
با توجه به این معماری و روشهای فشرده سازی اضافی (جادوی عصبی) ، قرمز قول داده است که مدل های آموزش دیده نیز روی سخت افزار قدیمی تر و ارزان تر اجرا می شوند و نیازی به آخرین کارتهای NVIDIA ندارند. سرور بدون در نظر گرفتن RHEL یا Open Shift قابل کار است. Red Hat ظروف بهینه و ایمن را در بغل کردن صورت دارد.

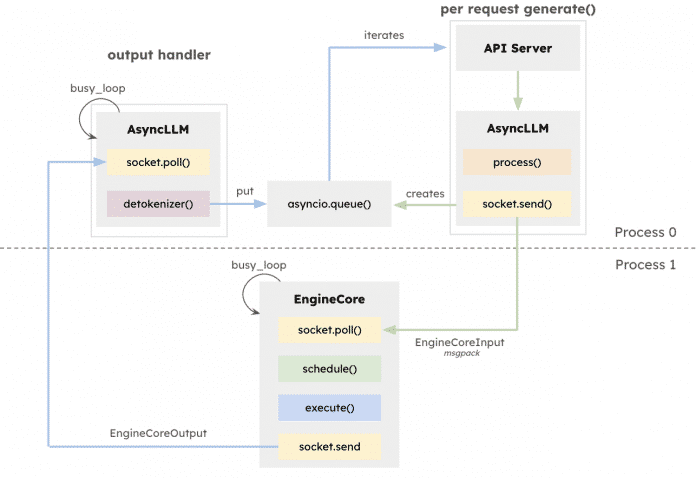
استنتاج بر روی موتور اجرا می شود و مسئول بهینه سازی حافظه است.
(تصویر: کلاه قرمز)
استنباط نشانگر عملکرد واقعی یک مدل کاملاً آموزش دیده است و رابط کاربران و سوالات آنها را نشان می دهد.
(سازمان بهداشت جهانی)
[ad_2]
لینک منبع



